
Cold on the heels of the last coding test review I did, I have decided to write up some thoughts on my attempts at a couple of Culture Amp’s coding tests.
I was originally forwarded Culture Amp’s web developer back end and front end tests a few years ago, so I cannot be certain whether they are still being used at the time of this writing, but I can at least confirm they were a part of their hiring process at one point in time.
In preparation for writing this post, I went back and cleaned out some digital cobwebs on my solutions, including changing continuous integration provider to GitHub Actions, and refactoring code to suit my current sensibilities around what I think “good” code looks like. But, for the most part, the main code structures have stayed the same.
I will review the back end test first, then the front end, and the companion codebases can be found here:
- Survey Tool Ruby (back end)
- Survey Tool Elixir (back end)
- Survey Tool Elm (front end)
Disclaimer: I am not, nor have ever been, an employee of Culture Amp, nor have I ever applied for employment there, nor is this post some kind of attempt to get them to employ me; I just did their coding tests for my own definition of “fun”.
If you are applying there, or plan to in the future, you may want to stop reading, and consider pretending that this blog post (and all the other solutions people have posted) does not exist, so you can greet their coding tests with fresh eyes.
Thematic Relevance
Before getting started, I would like to call out what I think is one of the strongest features of the tests: they are thematically relevant to the business.
When planning technical tests for candidates to perform, it can be tempting to just get them to do either an existing popular coding test, an example from a coding community like Exercism, or an obscure problem from some for-pay coding assessment platform. Culture Amp chose not to take this route: surveys would seem to be one of the primary mechanisms that their product uses to collect employee engagement feedback and gauge their well-being, and, to their credit, both custom coding tests revolve around them.

Original Back End Test Requirements
Your task is to build a CLI application to parse and display survey data from CSV files, and display the results.
Data Format
Survey Data
Included in the folder
example-dataare three sample data files defining surveys:
survey-1.csvsurvey-2.csvsurvey-3.csvEach row represents a question in that survey with headers defining what question data is in each column.
Response Data
And three sample files containing responses to the corresponding survey:
survey-1-responses.csvsurvey-2-responses.csvsurvey-3-responses.csvResponse columns are always in the following order:
- Employee Id
- Submitted At Timestamp (if there is no submitted at timestamp, you can assume the user did not submit a survey)
- Each column from the fourth onwards are responses to survey questions.
- Answers to Rating Questions are always an integer between (and including) 1 and 5.
- Blank answers represent not answered.
- Answers to Single Select Questions can be any string.
The Application
Your coding challenge is to build an application that allows the user to specify a survey file and a file for it’s results. It should read them in and present a summary of the survey results. A command line application that takes a data file as input is sufficient.
The output should include:
The participation percentage and total participant counts of the survey.
- Any response with a ‘
submitted_at’ date has submitted and is said to have participated in the survey.The average for each rating question
- Results from unsubmitted surveys should not be considered in the output.
Other information
Please include a Readme with any additional information you would like to include. You may wish to use it to explain any design decisions.
Despite this being a small command line app, please approach this as you would a production problem using whatever approach to coding and testing you feel appropriate. Successful candidates will be asked to extend their implementation in a pair programming session as a component of the interview, so consider extensibility.
General Approach
These requirements read to me like an “extract, transform, load” problem:
- survey raw data needs to be extracted from CSV files
- then parsed and transformed into a summary report
- then loaded (read: output) through the CLI
This thinking helped inform how the application architecture evolved, resulting in the responsibilities being split between three main modules:
survey_parser
Responsible for knowing how to open CSV files and read in their data rows. I also decided to slightly expand the scope of an “extractor” by having it take on some of the data transformation responsibilities: making it the bridge between raw data in files, and rich data structures within the application.
report
Responsible for collating all the disparate parts of the rich data together to present a structured report, in plain text, that was ready to be sent to the “loader”.
cli
Responsible for all functionality related to input and output on a terminal emulator. It parses CLI flags and arguments given to it, and prints out the text of survey report tables (or any errors) to the window.
Technical Choices
At the time I received the test, Culture Amp was hiring Ruby developers, so I decided to go with that flow. Ruby has a CSV module built-in to its standard library, meaning that the only application-level external library I chose to leverage was Terminal Table to help me construct the survey report.
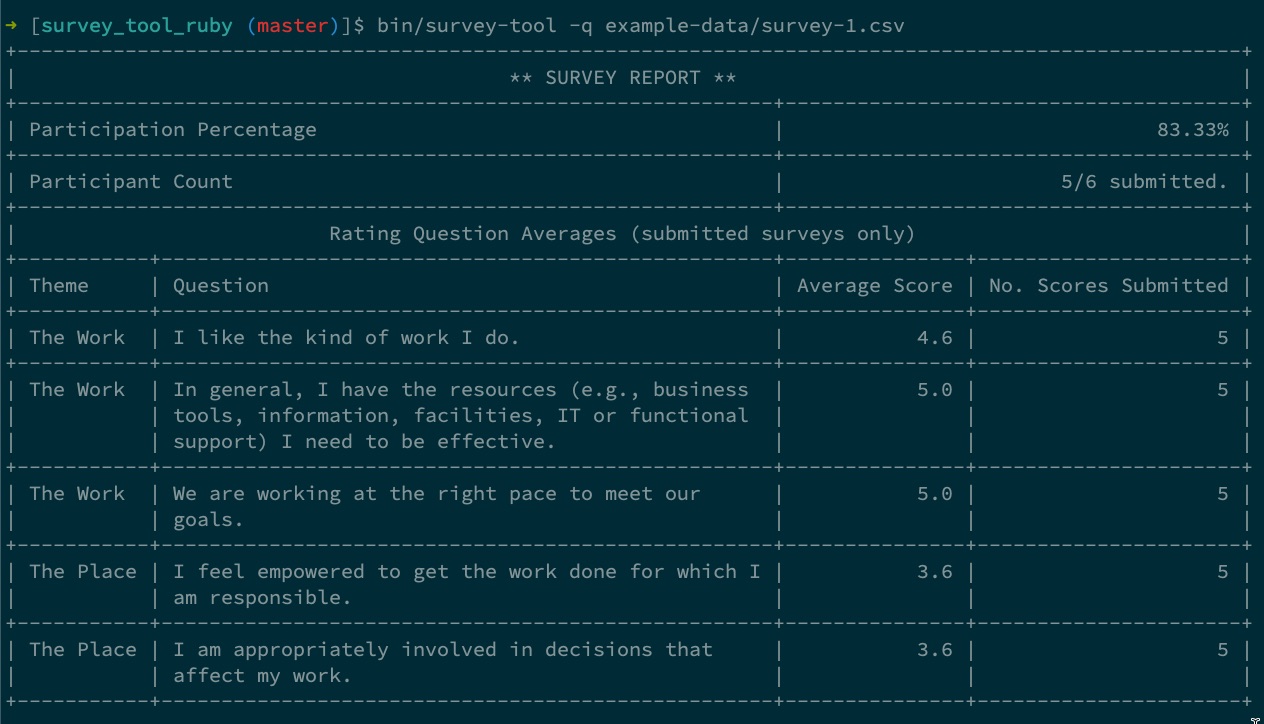
I try to make coding test solutions “showcase code”, and for me that means using as many development tools as possible that can help assess and (subjectively) affirm whether I have written code that is “acceptable” within the standards of the chosen language community. For this project, those tools were:
- minitest: Although I was more familiar with RSpec, I decided to use minitest due to my newfound affection for more terse syntax during testing, no doubt influenced from using ExUnit in my Elixir projects. No regrets; would use again
- SimpleCov: It seems to not be de jour as of this writing to aim for 100% test coverage, but I do anyway. I think if you write code that contains business logic, you should know what it does, and how it acts under a variety of circumstances: coverage gives me a litmus test to make sure I do not miss anything obvious
- Rubocop and Reek: I like having these little robots looking over my shoulder, slapping my wrist whenever I write code that could potentially violate the principle of least surprise to other Ruby developers
- YARD: Documentation is the most neglected part of many software application projects, so this was a personal challenge to just make sure I grind it out for great justice
With regard to code implementation choices, the following are a couple I think are worth making note of.
Facades
Facades are easily my favourite software design pattern, and you can see five of them in the codebase: wherever there is a “boundary” foo.rb file and a corresponding foo/ directory containing all of the Foo module’s implementation details. The front-facing foo.rb “API” file contains no real logic, and just delegates method calls to its child modules, masking complexity from other modules that call it.
Adapters
Whenever I need to leverage code from third-party libraries, like Terminal Table, I instinctively want to lock down and quarantine its use to a single module with an adapter, rather than have it permeate throughout the codebase. For this application, I would rather only have to change one module if I felt the need to change table libraries, rather than hunt through the codebase to find everywhere it is referenced. Therefore, you will only ever see Terminal::Table referenced inside SurveyTool::Report::Table.
I have even done the same thing with internal methods like good ol’ puts. It may be available everywhere thanks to it being a part of Ruby’s Kernel module, but I have made outputting to the terminal strictly the concern of the CLI module. So, I treat puts like a third party library, and force all code to go through CLI to get to it, in an adapter-like way. Is this too pedantic? Perhaps, but I still like having a single source of truth for specific functionality.

Take Two: Elixir
I enjoyed doing this test enough that I wondered how difficult doing a straight port of it to Elixir would be. To the surprise of probably no one who has experience with both Ruby and Elixir, it was fairly straightforward (though this is also likely due to Elixir having changed the way I write Ruby to have a more functional bent), but still a good learning experience.
The general approach and technical choices were mostly the same, with a few necessary tweaks like needing to use an external CSV library this time, and TableRex for the report. I could not get the display of the reports to mimic Terminal Table nicely, so I decided to make them look less table-like.
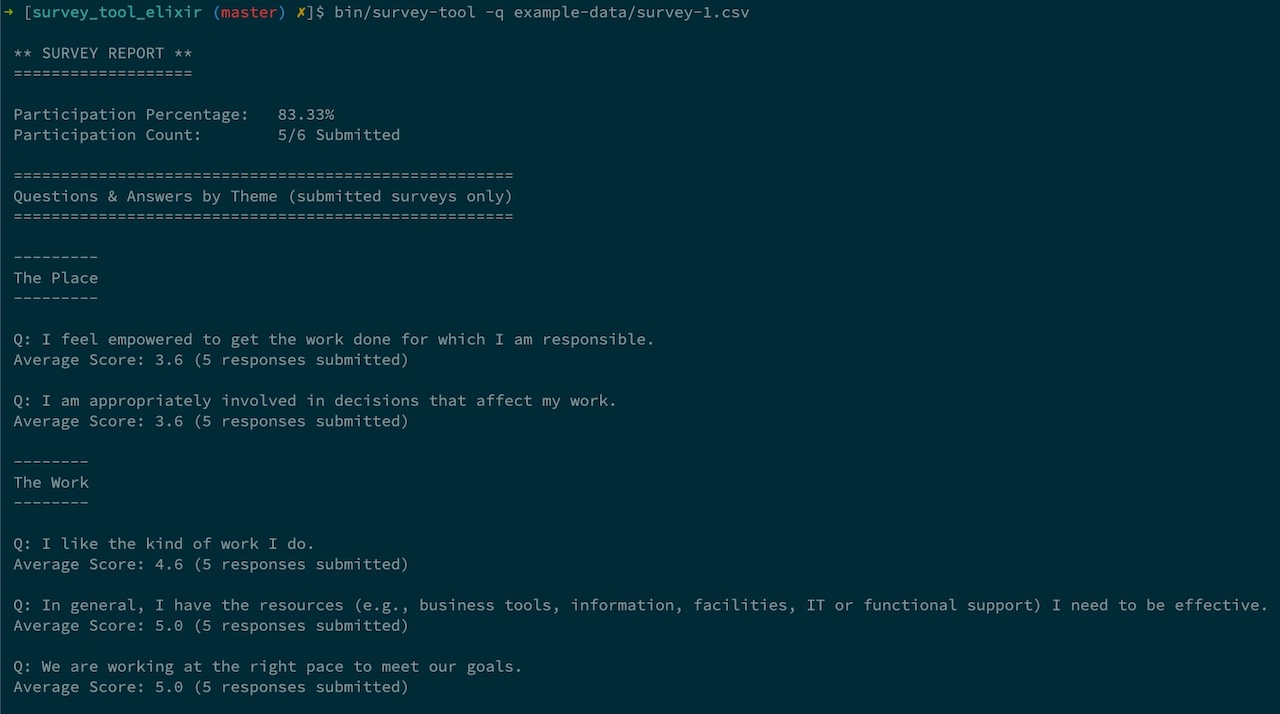
The flavour of the development stack was similar to the Ruby version as well: ExUnit for tests, ExCoveralls for coverage, Credo for code quality, and ExDoc for documentation.
Further to that, though, Elixir also has a nice Typespec notation that can be used with tools like Dialyzer, which makes for a great extra set of technical documentation (good for showcase code!), and can also help surface some kinds of bugs. So, I leveraged the Dialyxir and Gradient libraries to help keep an eye on my types during development.
Sharing Types
Speaking of types, probably my biggest learning regarding their use in Elixir during this portover was figuring out how to:
- surface a type declared in a internal module up to its facade boundary module
- have other modules be able to use those surfaced types without knowing some (or any) of their specific implementation details
Let’s illustrate this with an example. SurveyTool.Report.Table, an implementation detail module of SurveyTool.Report, needs to know about the SurveyTool.SurveyParser.Survey type as part of the typespecs of its render/1 function, as well as during pattern matching in its survey_body/2 function:
lib/survey_tool/report/table.ex
defmodule SurveyTool.Report.Table do
# ...
alias SurveyTool.SurveyParser.Survey
alias TableRex.Table
@spec render(Survey.t()) :: :ok
def render(survey) do
# ...
Table.new()
|> # ...
|> survey_body(survey)
end
defp survey_body(table, %Survey{participant_count: count}) when count < 1 do
table
end
defp survey_body(table, %Survey{questions: questions}) do
# add questions to table etc...
end
# ...
end
The encapsulation problem here is that SurveyTool.Report.Table is reaching past the SurveyTool.SurveyParser boundary, and into SurveyTool.SurveyParser.Survey, an implementation detail. So, how can we provide the SurveyTool.Report.Table module with the information it needs, at the SurveyTool.SurveyParser level?
Since SurveyTool.SurveyParser.Survey exposes its t() type in the following way…
lib/survey_tool/survey_parser/survey.ex
defmodule SurveyTool.SurveyParser.Survey do
# ...
alias __MODULE__, as: Survey
@typedoc "Survey struct type."
@type t() :: %Survey{
participant_count: integer,
questions: questions_list(),
response_count: integer
}
@typep questions_list() :: # ...
# ...
end
…we can “hoist” this type up to the SurveyTool.SurveyParser boundary module and expose it there:
lib/survey_tool/survey_parser.ex
defmodule SurveyTool.SurveyParser do
# ...
alias SurveyTool.SurveyParser.Survey
@type survey() :: Survey.t()
# ...
end
Now, we can change SurveyTool.Report.Table to bring in the survey() type and use it as its own private type (@typep):
lib/survey_tool/report/table.ex
defmodule SurveyTool.Report.Table do
# ...
alias SurveyTool.SurveyParser
alias TableRex.Table
@typep survey() :: SurveyParser.survey()
@spec render(survey()) :: :ok
def render(survey) do
# ...
Table.new()
|> # ...
|> survey_body(survey)
end
defp survey_body(table, %survey{participant_count: count}) when count < 1 do
table
end
defp survey_body(table, %survey{questions: questions}) do
# add questions to table etc...
end
# ...
end
After making this change, I did get a warning about variable "survey" is unused, but that can be silenced by changing %survey references to %_survey.
If a module using an external type does not need to know about the type’s implementation details, rather than expose the @type at the boundary, we can use @opaque instead (see survey_parser.ex and question_and_answers.ex in the companion codebase for an example of that).
Let’s now head over to web browser land and check out the front end test!

Original Front End Test Requirements
This repository contains a small number of static JSON files, which represent the responses from an HTTP API that offers access to a database of survey results.
Your task is to build a web front end that displays the data supplied by this API. You must process the survey data and display the results in a clear, usable interface.
Getting Started
We suggest you start by setting up an HTTP server that will serve up these JSON files upon request. This may be the same server that serves your web application to consume the API, but make sure to design your application in such a way that you could easily point it to an arbitrary base URL for the API, somewhere else on the Internet.
One you’ve got the API available, use whatever client-side libraries or frameworks you like to build the application that consumes it.
(Tip: If your application will access the API directly from the browser, using the same server for both your application and the API it consumes will save you having to deal with cross-origin requests. Of course, if you enjoy that sort of thing, feel free to go for it!)
The API
index.jsonis returned when you send a GET request for the root URL. It returns a list of the surveys that are stored in the database, and high-level statistics for each. For each survey, a URL is included that points to one of the other JSON files.The remaining JSON files each provide full response data for one of these surveys. Each survey is broken into one or more themes, each theme contains one or more questions and each question contains a list of responses. A response represents an individual user (
"respondent_id") answering an individual question ("question_id"). The content of each response represents an agreement rating on a scale of"1"(strongly disagree) to"5"(strongly agree). If you wished, you could obtain all of the responses for a single user by consulting all of the responses with that user’s"respondent_id".Requirements
Your application should include:
- a page that lists all of the surveys and allows the user to choose one to view its results;
- a page that displays an individual survey’s results, including:
- participation rate as a percentage
- the average rating (from 1 to 5) for each question
Responses with an empty rating should be considered non-responses (questions skipped by the survey respondent). These responses should be excluded when calculating the average.
You can deliver a set of static HTML pages that consume the API data with JavaScript, but keep in mind that we need to be able to read your code, so if you’re compiling your JavaScript in any way, please include your source code too. Alternatively, if you want to build an application that runs on its own web server, that’s okay too.
Recommendations
- Be creative in considering the right way to display the results.
- Feel free to use frameworks and libraries, but keep in mind that we are looking for something that demonstrates that you can write good front-end code, not just wire up a framework.
- Static JSON files load pretty quickly, but not all web APIs are so performant. Consider how your application will behave if the API is slow.
- Include a README file with clear build instructions that we can follow.
- Include in your README any other details you would like to share, such as tradeoffs you chose to make, what areas of the problem you chose to focus on and the reasons for your design decisions.
- We like tests.
Beyond meeting the minimum requirements above, it’s up to you where you want to focus. We don’t expect a fully-finished, production-quality web application; rather, we’re happy for you to focus on whatever areas you feel best showcase your skills.
Submitting your solution
Assuming you use Git to track changes to your code, when you’re ready to submit your solution, please use
git bundleto package up a copy of your repository (with complete commit history) as a single file and send it to us as an email attachment.git bundle create front-end-coding-test.bundle masterWe’re looking forward to your innovative solutions!
Approach
In my experience, back end web developers tend to not need to write that many CLI applications, so these requirements feel more representative of the kind of work a front end web developer actually does on a more regular basis. However, there is no designer handing you a pretty interface to implement, here: you have to muster up your own creativity in determining how to display the data. This put me out of my personal comfort zone, so it was a good test to force me think more about web page design than I usually would.
For the HTTP server, since my head was already in Elixir-land from the back end test, I chose it to serve up the static JSON files. Using a full blown web application framework like Phoenix for this seemed like overkill, so I just used an Elixir application with Plug.Cowboy, which worked out perfectly.
For the web front end, since Culture Amp was actively using Elm at the time I received the test1, I chose it to write a web application. I employed a similar set of design principles and development tools to the back end: elm test and elm-verify-examples for testing, Elm Coverage for test coverage, as well as Elm Analyse and elm-review for code quality control.
Design
Design and writing CSS are some of my weak points, so I decided to leverage a “functional CSS” library to help me out with making things look nice enough for something designed by a developer that leans more to the back of the stack. At the time I wrote the solution, it seemed like Tailwind CSS and Tachyons were battling it out for developer mindshare, and I ended up choosing the latter solely based on a friend’s recommendation.
For the general colour scheme, I started with just basic black, white, and grey, with splashes of the pink colour that Culture Amp (now previously) used for its branding. I kind of like how it turned out, so I did not iterate further on the colours, though that could just be indicative of a lack of creative flair on my part.
Here is how the pages turned out.
Survey List Page
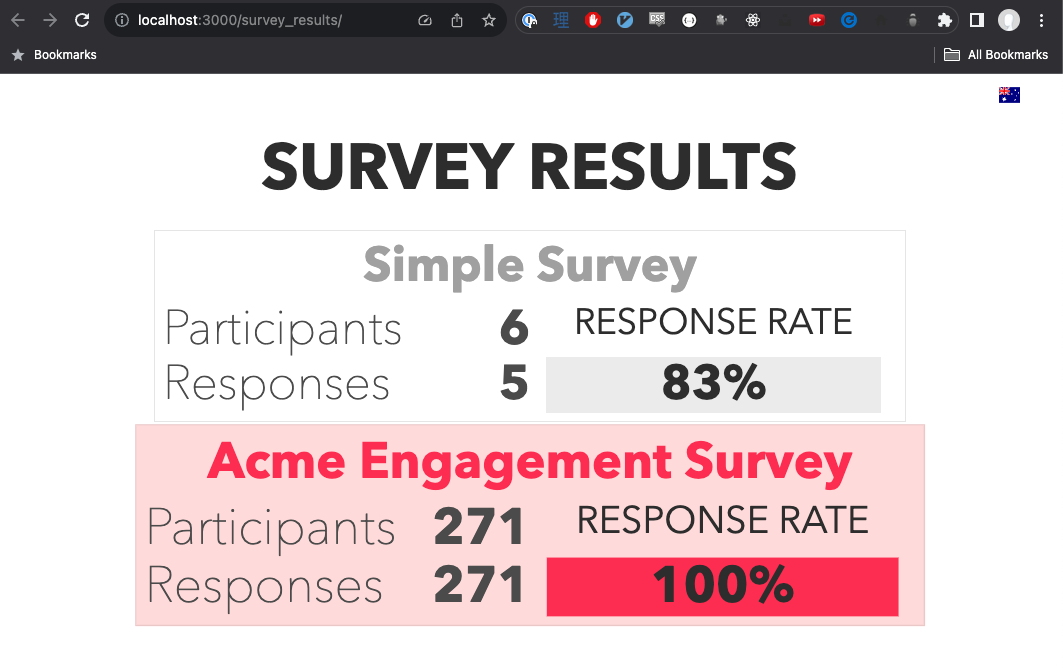
The survey list page is a fairly straightforward display of data of the JSON data in a list-like format. Since I was experimenting with Tachyon classes, I added very small flairs of slightly embiggening the item, as well as changing its colours, on mouseover.
This screen shows the success case of actually being able to fetch the JSON data, but when the app is still fetching the data, or the fetching fails, then an appropriate loading or failure page is shown. The Elm code leverages the RemoteData for Elm package to help manage these states.
Survey Detail Page
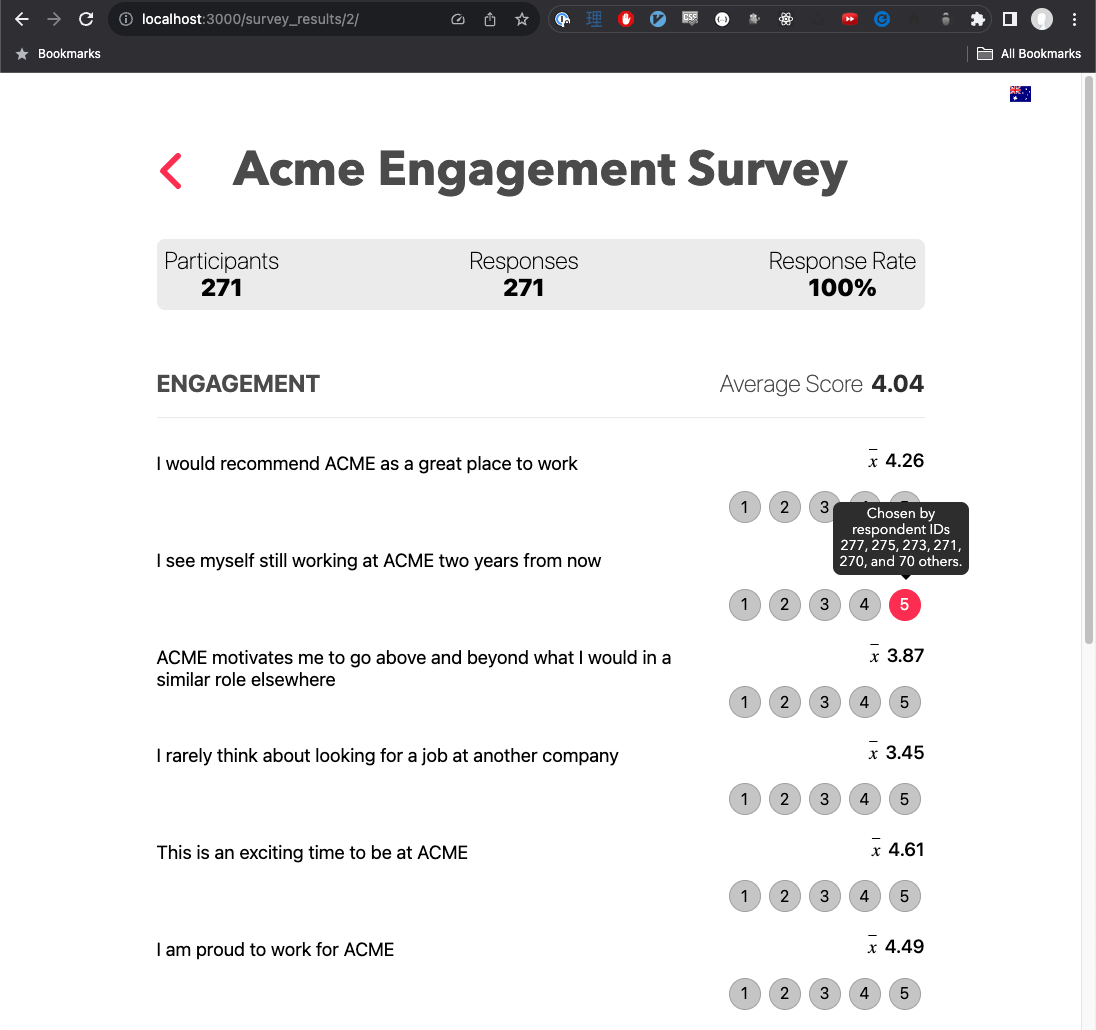
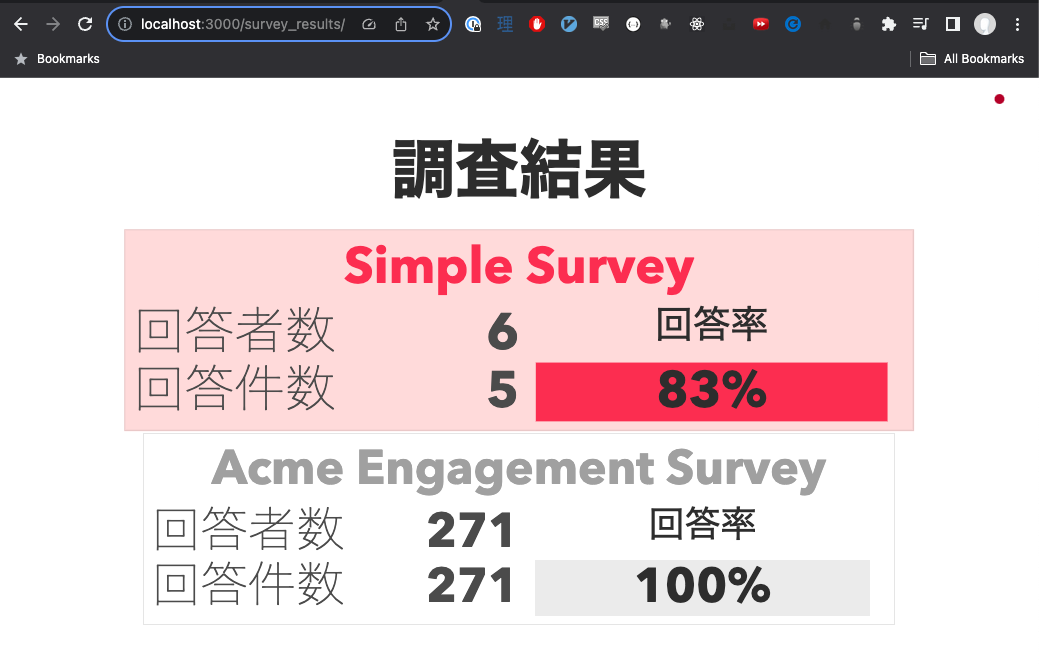
The survey detail page is presented in a similar way to how the back end app output its data to the terminal: summary data is repeated at the top of the screen, and then all the questions are presented in a table style format.
Use of the word “average” for every score felt a bit repetitive, so I changed it to x. However, if I re-wrote this page again, I would probably reconsider using what may not be a widely known notation for “average”.
Tooltip Histogram
I believe that displaying the participation percentage, and the average score for each question, technically clears the display requirements. But, I was curious about being able to display the questions in such a way where you could get an idea about how many respondents chose a specific score for a question, and who specifically chose each score. That curiosity led to creation of the tooltip histogram you can see in the screenshot above, which shows when mouseover-ing a score.
Inspired by the way Facebook displays post likes, I decided to shamelessly rip it off to show the respondent histogram. Since the data only contains user IDs, it is limited in what it can display, but I think it is a nice bit of extra functionality, and a good example of what other information can be derived from a data set by doing some folding.
You could say that the result ended up being adjacent to the optional test requirement of “if you wished, you could obtain all of the responses for a single user by consulting all of the responses with that user’s respondent_id”: instead, though, we get “all the users for a single response”.
Internationalisation
Finally, completely out of scope of the requirements (but not something whose addition detracts from anything), is internationalisation, something I value highly in applications.
I added in switchable app-level translations in Italian and Japanese (via a flag menu at the top of the screen), but obviously this does not extend to any information that comes in from the JSON files. You can read more about my adventures with internationalisation in Elm in Runtime Language Switching in Elm.

Conclusion
Overall, I enjoyed doing these tests. I think they both struck a good balance between hard requirements, and freedom to solve problems creatively. Their appropriate business-level theming gave them a sense of being grounded in reality, which, as well as holding the interest of a candidate, can help avoid hiring-side doubts when using generic tests (“well, we know they can write a bogosort, but can they do what we actually need them to do everyday?”).
Personally, when I see that time, effort, and thought has been put into creating new coding tests, it leaves a great first impression on the technical culture of an organisation, and makes me want to leave one as well by submitting the best solution I can. If you, as an organisation, have the time, resources, and ability to create your own custom tests (assuming you do use them, of course), then I would highly recommend it!
-
As of this writing, Culture Amp has stopped using Elm for new code and is “containing” its usage in their codebases moving forward. Their Director of Engineering, Front End, Kevin Yank, in what I consider to be a stellar example of pragmatic technical leadership, outlined why in On Endings: Why & How We Retired Elm at Culture Amp, and further discussed it on the Elm Town #54 podcast. I highly recommend checking them both out (even though it is sad that Elm lost one of its most high profile early adopter organisations)! ↩




Leave a comment