Furigana are annotations used to indicate the Japanese reading, or pronunciation, of Chinese kanji characters.
As a simple example, let’s say we have a character like this1:
車
Furigana for the kanji, written with hiragana2, can be placed above it3:
車
This is all well and good for Japanese speakers, but what if I wanted English-speakers to be able to read along as well? This can be done by adding the character’s pronunciation using Latin script (romaji) as another furigana-style annotation:
車
Okay, but what does this word actually mean? We could put an English translation to the right of the word, or pile on yet another annotation for the English meaning4:
車
For single words, this “full-suite” of annotations could be considered acceptable, but for complete sentences, where the objective is to have a non-Japanese speaker read along phonetically, I think any translation needs its own dedicated section.
I did exactly this in a previous blog post, A Person’s Character (人という字は), where I wanted to show the pronunciation and meaning of some lines of dialogue from the television drama Kinpachi-sensei. The intention was to enable English speakers to follow the Japanese dialogue using the romaji annotations, and then read the translation:
Can I have your attention, please. So, the character for "person" consists of one person holding up and sustaining another person. In other words, it is a "person" precisely because a person and another person are supporting each other. A person gets support from other people and their community, and through that support, grows and develops as a human.
Figuring out the idiosyncrasies of how to mark-up and display all of these annotations in the way I wanted using HTML and CSS, and then developing a way to extract that logic out into functionality that could be shared across multiple Markdown-based blog posts using Liquid, took me far more time than I expected, and became the catalyst for writing this particular blog post.
So, the following is my brain dump on what I learned about using annotations on the web.
Furigana is a type of Ruby character annotation5, and is marked up in HTML using the <ruby> tag.
Searching the internet for how to mark-up <ruby> elements leads to a significant amount of conflicting information. The W3 Ruby Annotation document mentions a selection of markup tags that can appear inside a <ruby> tag:
<rp>: ruby parenthesis (for when a browser does not support ruby annotations and the ruby text gets rendered inline)
<rb>: ruby base (the text that is being annotated)
<rtc>: ruby text container (a container for <rt> elements when markup is “complex”)
<rbc>: ruby base container (a container for <rb> elements when markup is “complex”)
Each of the tag links in the list above is from the Mozilla HTML documentation, a trustworthy source for this kind of information (in my opinion), and they say that the <rb>, <rtc>, and <rbc> tags are deprecated, and should be avoided. In order to future-proof furigana annotations, it would seem that only three tags should be used: container <ruby> tags, along with child <rt> and <rp> tags.
So, for the “car” kanji from the example above, 車, the markup could look like the following:
What are those <rp> tags for? In the event that a browser does not support ruby annotations, the code above will display as:
車(くるま)
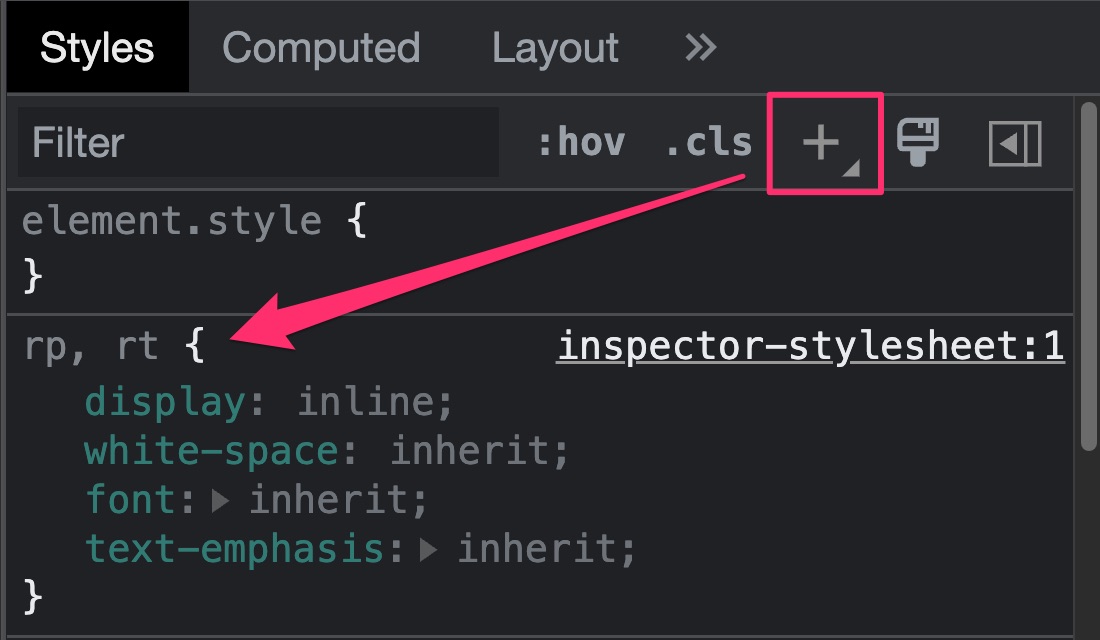
I could not find any built-in functionality that would force a modern browser to “pretend” it does not support annotations, but I was able to follow the Inlining Ruby Annotations section of CSS Ruby Annotation Layout Module, and add styling via the browser developer tools to achieve the desired display behaviour:
Given that the HTML spec for the <ruby> element says that a <ruby> tag can contain “one or more <rt> elements”, you may be forgiven for thinking that adding the extra romaji annotation would be a case of perhaps appending it beneath the furigana:
Not great. We can, however, rearrange the <ruby> child elements, and leverage CSS Flexbox styling, to exhert more control over the visuals (we will keep styling inline for demonstration purposes moving forward):
This displays in a similar way to the initial example at the beginning of the post (though the default gap between the kanji and furigana is a bit concerning…). However, I think the meaning behind the child elements of the <ruby> parent tag have become muddled.
What is annotating what? Is 車 annotating kuruma, along with くるま annotating 車? Technically, it seems these semantics are valid, but is there is another way to communicate the desired annotations via markup?
Note, also, that we have headed into exploitation territory for the meaning of the <rp> tag to make sure that we get 車(くるま, kuruma) displayed when annotations are not supported (commas are not parentheses, after all). I do not currently know of a “better” way to mark this up to allow for a similar kind of display.
The code examples in the HTML spec for the <ruby> element show that “a nested <ruby> element” can be used for inner annotations. In our case, this could mean that the markup should indicate that:
くるま annotates 車 (one <ruby> inner nested element)
kuruma annotates the 車 compound (another <ruby> outer nesting element)
Looks acceptable to me, and I think the meaning of the markup is conveyed in a clearer way.
Nesting <ruby> tags like this means we have to give up the ability to display the furigana and romaji together [車(くるま, kuruma)], when annotations are not supported. But, I am prepared to accept this compromise because the fallback display looks good enough for the rare times it will probably ever be viewed:
車(くるま)
kuruma
Before concluding that we have the <ruby> markup and styling to use as a foundation to build with, let’s test it with a few other kanji scenarios.
Single Word, Multiple Kanji
Not every word in Japanese can be written with a single kanji; many require multiple kanji together in a compound. So, let’s test the current markup’s display of kanji compounds by changing the “car” into an “automobile”:
This looks like it displays as expected. However, pedanticism is going to get the best of me here: even though the furigana is correct for the entire word, they don’t quite line up perfectly above the individual characters they are annotating the reading for.
Let’s see if we can fix that by adding more <rt>/<rp> tag sets:
Ah, much better! The difference may be minor, but I think it’s important!
Doing this, unfortunately, “breaks” the <rp> fallback display even more, as the furigana readings are now displayed broken down not by full word, but by character:
自 (じ) 動 (どう) 車 (しゃ)
jidōsha
At this point, I think attempting to handle the fallback display gracefully is going to be prioritised to a distant second compared to getting the furigana displaying well for “normal” modern browser usage.
Single Word, Alternating Kanji and Kana
Compound verbs in Japanese are a good example of words that alternate between kanji and kana in their construction. For example, in the annotations for the word norikomu (乗り込む), meaning “to get into (a vehicle)”, I would expect there to be furigana over 乗 and 込, but not over り or む. As for the romaji, I think a single annotation under the word would suffice.
Let’s see if we can re-use the code from the kanji compound to achieve the effect we want:
Hmm, not quite right: that second furigana positioning is incorrect, and there is an awkward space between 乗り and 込む. Perhaps each half of this word needs to be its own <ruby> element? Let’s give that a try:
The furigana positioning is fixed, but since we now have three child elements under the <ruby> tag, the flex-direction: column styling is displaying them all vertically, which is not the result we want.
In order to get them to display as one set, we will need to wrap a container around the 乗り and 込む <ruby> tags. Yet another <ruby> tag seems like it could be overkill here, so, instead, let’s try a plain old <span> tag, and give it some Flexbox styling as well:
Looks good to me! If we did want to split the romaji, so the annotation was under each part of the word, we have the option of changing the tag nesting around to achieve that effect:
Great! We now know there are options around the display for romaji, for potential readability and/or aesthetic reasons.
Styled Furigana
Speaking of aesthetics, does furigana still display as expected if the CSS font-style changes, like how everything gets italicised on this page when the content is within <blockquote> tags? Let’s find out with the phrase 自 動 車 に 乗り 込む (“to get into the automobile”):
Well, it seems that annotations do not really understand italics; they look a tiny bit off, don’t they? It would be nice to be able to nudge them a bit to the right on an individual character basis.
Luckily, this is a simple matter of just adding in some text-align styling in the <rt> tags:
This looks a tiny bit better, though it seems to be more effective for single character furigana than those for compound characters. Pushing the furigana any further to the right would involve adding some padding-left attributes to the <rt> tag (which could push the kanji into places you may not want), so feel free to experiment on getting the alignment just right for your tastes.
Finally, let’s just confirm the markup works for some exceptional circumstances.
Long and Short Furigana
There are some words in Japanese where up to five syllables can be represented by a single kanji. Let’s use the markup with uketamawaru a word that fits these conditions, and means “to be told” or “to receive (an order)”:
I think this display is okay, given the awkwardness of the furigana to kanji ratio. But, that gap between 承 and る just seems too big to me, and makes me wonder whether allowing for more flexibility in the size of the furigana annotation would make it less unwieldy.
Let’s see what happens if we give the furigana a smaller absolute CSS font-size value:
Much better, I think, and it can be adjusted to preference on a per-character basis.
Now, what about the opposite scenario, when there are more kanji than furigana characters? This will only really happen with so-called Special Readings, which occur frequently with geographical or human names. So, let’s try the markup with a good example of this, the surname Hozumi:
I think this display of ほずみ6 looks fine. The spacing of the furigana may look a bit strange, but since there is no correlation between the annotation and the pronunciation of each individual kanji, having them spread out evenly across the top of the word, or center-aligned, is probably the most logical way to display them.
Markup Reuse
As you can see from the chunky markup blocks above, annotations can take up a lot of coding space. Personally, I do not want to have to manually write <ruby> tags every time I want to insert a Japanese word with any kind of annotation into my blog posts, so I wanted a way to reuse that markup.
Jekyll is the engine that currently powers this blog, and it allows the usage of Liquid, a templating language, which has enabled me to put <ruby> code into functions that take parameters to fine-tune how annotations should display. These functions are littered throughout the code for this blog post, as well as other Japanese language-related posts, and fall into two main groups.
Basic Ruby Tags
These are functions that wrap around <ruby> tags for purposes of general annotation, and are not specific to Japanese (though they can certainly be used that way). Some examples used in this blog post that you may have noticed are:
There are also functions that take in parameters which allow all the fine-tuning customisations to furigana and romaji we have seen in the examples above, and are hence specific for use with Japanese. Under the hood, they all leverage the {% include ruby.html %} function. Some examples used in this post are:
Going through the details of these functions is something I will leave up to the interested reader7. You can find all the code in the _includes/ directory of this blog’s codebase.
Much Ado About Annotations
For such small text, the coding, display, debugging, and refactoring of furigana has taken up a significant amount of my time and brain space. However, I still do not really know if I am doing it “right”.
The developers over at the Japanese Language Stack Exchange, whom I assume are experts at all things Japanese for the web, would seem to eschew <rp> and <rt> tags for <span> tags in order to represent <rt> and <rb> values for their cool furigana pop-ups:
However, NHK Easy Newsdoes use <ruby> and <rt> tags in the same way as the examples in this post. However, they, too, have opted to not use <rp> tags (perhaps they considered them to be legacy/unnecessary…?).
Yahoo News Japan does not support furigana annotations at all, preferring instead to display <rp>-style parenthesised kanji readings inline (perhaps because they are a bit Web 1.0-in-the-tooth, and still want to support browsing on Galápagos phones, which display pages using cHTML, a subset of HTML that does not support <ruby> tags).
Regardless, this post represents everything I think I know about furigana for the web, and now you know it, too. If new information comes up, or the specification for use of <ruby>-related tags changes, I am definitely happy to revise any content. If there is something I have missed, please reach out and let me know!
All Japanese character displays were confirmed to work as expected on Google Chrome. So, if you use another browser, and explanations do not quite match the display, that would be why. ↩
Placed above when the kanji is written left-to-right horizontally (yokogaki), but placed to the right when written right-to-left vertically (tategaki). ↩
Or, you could use a browser extension like Rikaichan or Rikaikun, which display pop-up kanji readings and English translations when you mouse over them, making any lack of annotations irrelevant. For purposes of this post, we’ll pretend they do not exist (I still absolutely recommend using them, though!). ↩
The name of which is from an old British typography type that had a height of 5.5 points, and not to be confused with anything related to the Ruby programming language. ↩
As well as ほずみ , 八月一日 can be read as ほづみ , やぶみ , and はっさく . ↩
It was tough to keep my own interest up with Liquid since I found using it so frustrating, even after changing my mindset to thinking of it as “smart HTML rather than dumb Ruby”. Nevertheless, I got what I wanted in the end after significant trial and error; hopefully, you can save yourself some time and irritation by using the code if you have similar use cases. ↩






{kind=link}
Leave a comment